
Butler Labs is an AI-powered optical character recognition (OCR) platform with models fine tuned to extract important data from a variety of commonly encountered documents:
- Driver’s Licenses
- Passports
- Health Insurance Cards
- Paystubs
- Invoices
- Receipts
- W9s
- Mortgage Statements
What makes this platform even more attractive from a developer standpoint is that they provide a generous free tier of 500 scans per month and a comprehensive REST API. This means you can basically add an OCR upgrade to your app today.
Setup
API Key
To start using the Butler Labs OCR product, you’ll need two values:
- An API key
- A model-specific queue ID
After creating an account, you’ll find your API key at the top of the “Settings” page. The API key is a sensitive value that enables access to your account. For that reason, you should avoid adding it to version control and instead pass it to your app using dart-define:
flutter run --dart-define BUTLER_API_KEY=1234567890Or my preferred method, dart-define-from-file. First create a config.json file in your app’s asset folder:
{ "BUTLER_API_KEY": "YOUR_KEY",}Then run your app using the following command:
flutter run --dart-define-from-file=assets/config.jsonInside the app, you can retrieve dart-define values using the String.fromEnvironment() constructor:
String apiKey = const String.fromEnvironment("BUTLER_API_KEY");Queue ID
In this post, we’ll be using the US Driver’s License model to extract a ton of information from images of driver’s licenses. Before we can do this though, we’ll need a queue ID (aka API ID) for our instance of the model. On the “Explore Models” page, locate the US Driver’s License model.
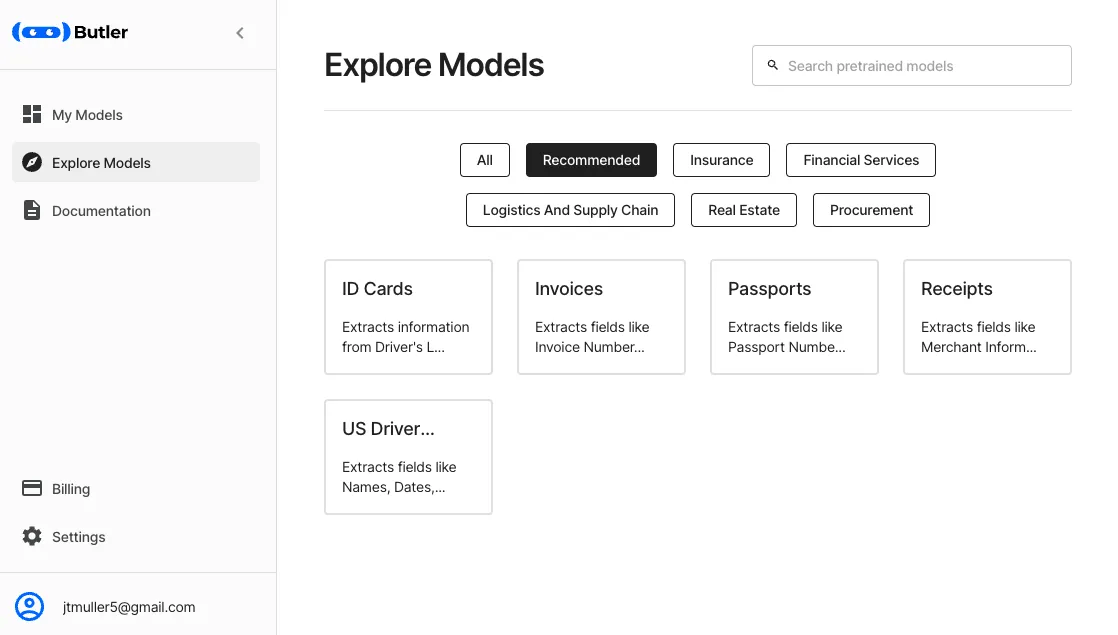
The process for adding any model is the same:
- Click on it to add it to your “My Models” page
- On the “My Models” page, select the new model
- Select the “APIs” tab
- Copy the queue ID at the top of the page
Image Picker
Users will need to either capture or upload images to your app so they can be analyzed and by far the easiest way to accomplish this is with the image_picker package. It works seamlessly on Android, iOS, and the mobile and desktop variants of web. Add the dependency to your pubspec.yaml:
dependencies: image_picker: ^1.0.0And then create a simple button that users can tap to take an image.
ElevatedButton( onPressed: () async { ImagePicker picker = ImagePicker(); XFile? pickedImage = await picker.pickImage(source: ImageSource.gallery); if (pickedImage == null) return; // todo analyze image }, child: const Text('Upload Image'),),In the next step we’ll send the user’s image to Butler Labs and parse the result.
A Driver’s License Example
In this post, we’ll running our tests on the sample licenses from the Driver’s licenses in the United States Wikipedia page.

Click on each one separately on the wiki and download it. Once you have an image on your computer, you can drag it onto your Android emulator to add it to the list of files.
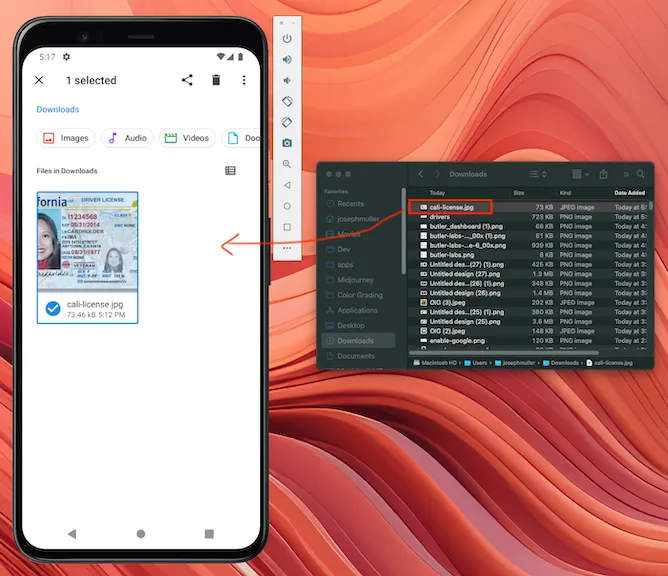
Now onto the fun part!
Making the Request
After a user selects an image, we want to send it to the extract endpoint where Butler Labs will analyze it and return a JSON object with the parsed results. An example response looks like this:
{ "documentId": "1540d070-c500-4994-a0bc-4196499c41de", "documentStatus": "Completed", "fileName": "alabama.jpeg", "mimeType": "image/jpeg", "documentType": "US Driver's License", "confidenceScore": "High", "formFields": [ { "fieldName": "Document Number", "value": "1234567", "confidenceScore": "High" }, { "fieldName": "First Name", "value": "CONNOR", "confidenceScore": "Low" }, { "fieldName": "Last Name", "value": "SAMPLE", "confidenceScore": "High" }, { "fieldName": "Birth Date", "value": "01-05-1948", "confidenceScore": "High" }, { "fieldName": "Expiration Date", "value": "01-05-2014", "confidenceScore": "High" }, { "fieldName": "Address", "value": "1 WONDERFUL DRIVE MONTGOMERY AL 36104-1234", "confidenceScore": "High" }, { "fieldName": "Sex", "value": "SEXM", "confidenceScore": "High" }, { "fieldName": "State", "value": "Alabama", "confidenceScore": "High" } ], "tables": []}The image files need to be sent to the API in a Multipart request. Luckily the http package comes with out-of-the-box support for this so the first step is to import that and a few others:
import 'dart:io'; // For the HttpHeadersimport 'dart:convert'; // To decode the response from Butler Labsimport 'package:http/http.dart'; // For the MultipartRequest classimport 'package:http_parser/http_parser.dart'; // For the MediaType classThen, you need to create the MultipartRequest using the extract endpoint. This is also where you’ll add your API key to the request header:
String butlerApiKey = const String.fromEnvironment('BUTLER_API_KEY');
MultipartRequest request = MultipartRequest('POST', Uri.parse('https://app.butlerlabs.ai/api/queues/$queueId/documents'));
request.headers.addAll({ HttpHeaders.acceptHeader: '*/*', HttpHeaders.authorizationHeader: 'Bearer $butlerApiKey', HttpHeaders.contentTypeHeader: 'multipart/form-data', });Finally, we need to add the image to the request. This can be done using the image’s file path or its raw bytes and the option you choose will depend on the platform you’re using. Files returned by ImagePicker on Flutter web will not have a path so on the web you will need to use the bytes method. I’ve included the full code snippets for both methods below.
Using the Image Path
ElevatedButton( onPressed: () async { ImagePicker picker = ImagePicker(); XFile? pickedImage = await picker.pickImage(source: ImageSource.gallery); if (pickedImage == null) return;
String butlerApiKey = const String.fromEnvironment('BUTLER_API_KEY'); String queueId = 'fdf1f80a-03f5-40e5-83f0-a33694318532'; // Replace with your own queueId
MultipartRequest request = MultipartRequest('POST', Uri.parse('https://app.butlerlabs.ai/api/queues/$queueId/documents'));
request.headers.addAll({ HttpHeaders.acceptHeader: '*/*', HttpHeaders.authorizationHeader: 'Bearer $butlerApiKey', HttpHeaders.contentTypeHeader: 'multipart/form-data', });
if (defaultTargetPlatform == TargetPlatform.android || defaultTargetPlatform == TargetPlatform.iOS) { request.files.add( await MultipartFile.fromPath( 'file', pickedImage.path, contentType: MediaType('image', 'jpeg'), ), ); } else { throw Exception('Platform not supported'); }
StreamedResponse response = await request.send();
ButlerResult? result; String value = await response.stream.transform(utf8.decoder).join(); result = ButlerResult.fromJson(jsonDecode(value)); debugPrint('Response stream: $value'); }, child: const Text('Upload Image'),),Using the Image Bytes
ElevatedButton( onPressed: () async { ImagePicker picker = ImagePicker(); XFile? pickedImage = await picker.pickImage(source: ImageSource.gallery); if (pickedImage == null) return;
String butlerApiKey = const String.fromEnvironment('BUTLER_API_KEY'); String queueId = 'fdf1f80a-03f5-40e5-83f0-a33694318532'; // Replace with your own queueId
MultipartRequest request = MultipartRequest('POST', Uri.parse('https://app.butlerlabs.ai/api/queues/$queueId/documents'));
request.headers.addAll({ HttpHeaders.acceptHeader: '*/*', HttpHeaders.authorizationHeader: 'Bearer $butlerApiKey', HttpHeaders.contentTypeHeader: 'multipart/form-data', });
Uint8List imageBytes = await pickedImage.readAsBytes();
MultipartFile file = MultipartFile( 'file', ByteStream.fromBytes(imageBytes), imageBytes.lengthInBytes, filename: 'temp.jpg', contentType: MediaType('image', 'jpeg'), );
request.files.add(file);
StreamedResponse response = await request.send();
ButlerResult? result; String value = await response.stream.transform(utf8.decoder).join(); result = ButlerResult.fromJson(jsonDecode(value)); log('Response stream: $value'); }, child: const Text('Upload Image'),),The bytes method will work on all platforms so I suggest using that
Deciphering the Results
The request may take a few seconds but soon you should have a nice, juicy JSON blob to sink your teeth into. The shape of the result is fairly consistent from model to model too, meaning you won’t have to build custom deserializers if you add more models later.
Each result will contain the following top-level fields:
- Document ID: Unique ID for the document you uploaded
- Upload ID: An ID you can use to delete the image that was uploaded
- Document Status: A value indicating the status of the document according to Butler Labs
- File Name: The name of the file that was uploaded
- Document Type: The type of the document, typically matching the model you used (ex. Health Insurance Card)
- Confidence Score: A Low/Medium/High value indicating the model’s overall confidence in the parsed results. You can see the breakdown of all your organization’s confidence scores on the Butler Labs dashboard
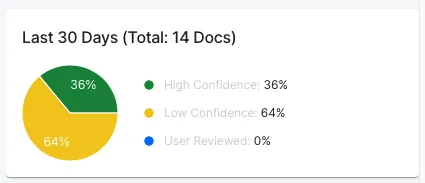
Beneath these top-level fields you will also find a list of “Form Fields” corresponding to the fields identified by your model (see the model’s page in the Butler Docs). Each form field will contain the following values:
- Field Name
- Value: The value detected by the model for this field
- Confidence Score: A Low/Medium/High value indicating the model’s confidence in this specific field
- Confidence Value: A value between 0 and 1 indicating the likelihood the result is correct
- OCR Confidence Value: A value between 0 and 1 indicating the likelihood the model found the correct field
In the sample app linked below, I used the confidence scores and values to create a simple UI illustrating the model’s performance:
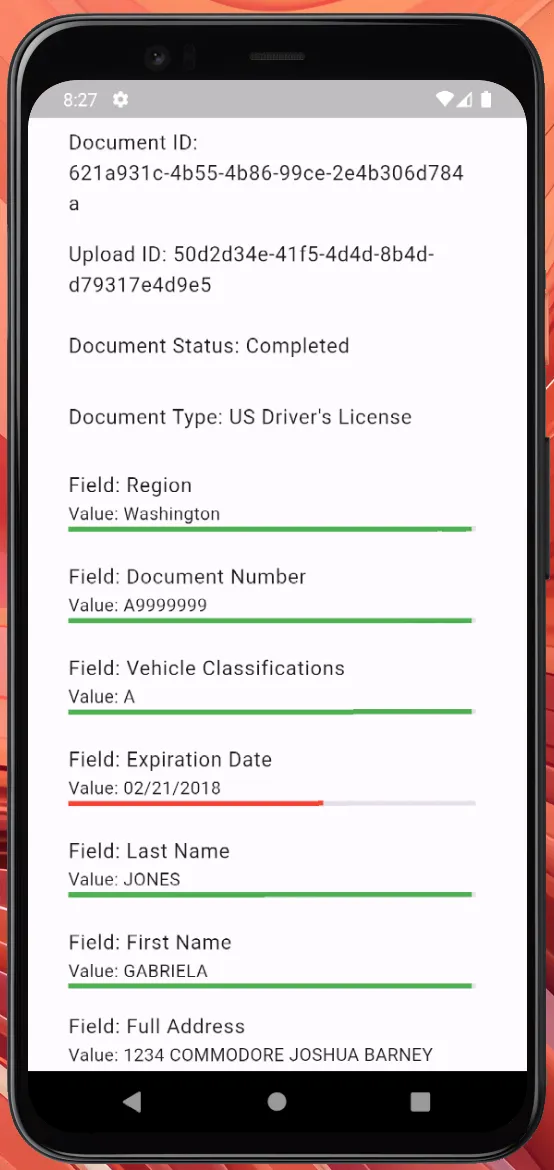
Butler Labs Package
While the code required for this OCR product is fairly unsophisticated, you can avoid the hassle of piecing everything together yourself and use the butler_labs package on pub.dev. This package currently only supports the Extract document endpoint. It includes a generic ButlerResult class and models specific to each model on the Butler Labs Website so you can convert the generic result from the API into something that’s more usable.
Conclusion
OCR is a solved problem and Butler Labs has a product that is more than satisfactory for many common use cases. If the built-in models don’t meet your needs, their platform also allows you to create your own models. You can read more about that here. Happy coding!
Copyright © 2024 Code On The Rocks. All rights reserved.